AI人声分离:如何高效分离音频中的人声与音乐?工具推荐与操作指南
在音频处理领域,怎么把音频里面的说话声和音乐分开?传统方法依赖人工调参或基础滤波技术,但效果有限。随着人工智能技术的突破,深度学习算法为音频分离提供了更高效、精准的解决方案。
一、技术原理:深度学习驱动的智能分离
音频分离的核心在于利用算法模型识别并分离混合信号中的不同声源。传统方法(如频谱编辑、中置声道提取)依赖人工调整参数,存在以下局限:
频谱编辑法:需手动调整频段音量,操作复杂且对复杂音频效果不佳;
中置声道提取法:基于立体声相位特性,但人声与乐器可能混杂,分离纯净度不足。
AI技术的引入彻底改变了这一局面。基于深度学习的分离模型(如U-Net、Demucs)通过大量数据训练,能够自动学习人声与乐器的频谱特征、谐波结构等差异,实现更高精度的分离。
二、人声分离工具推荐
陆玖拾贰人声分离是一个支持在线使用的AI音频处理工具,它适合快速分离的场景,无需安装,支持MP3、WAV等主流格式;操作简单是需要“上传音频→AI自动处理→下载分离结果”这三个步骤即可完成。
三、怎么把音频里面的说话声和音乐分开
以下以陆玖拾贰人声分离为例,演示在线分离的完整流程:
步骤1.访问并登录陆玖拾贰人声分离官网页面,选择“人声分离”功能。
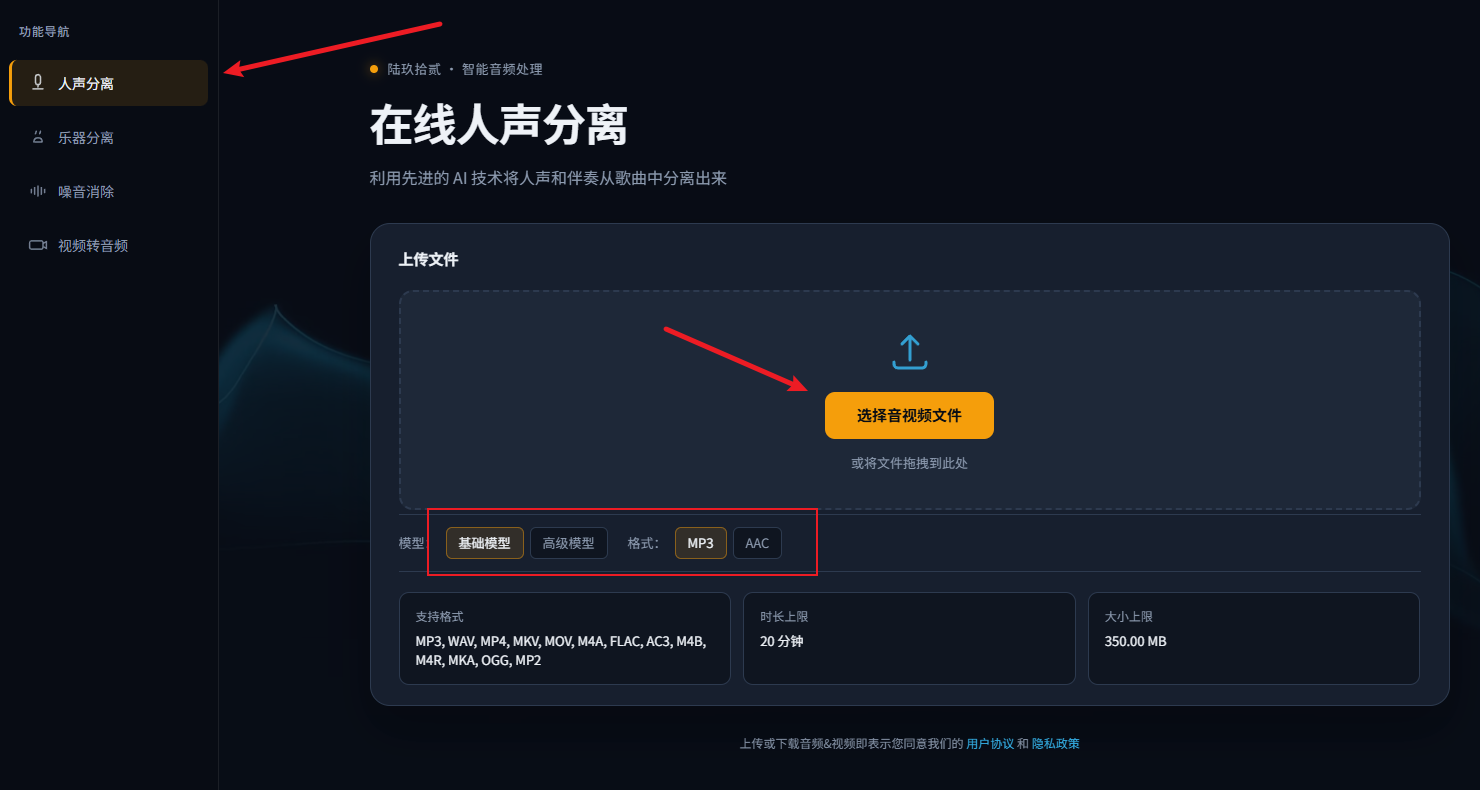
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。
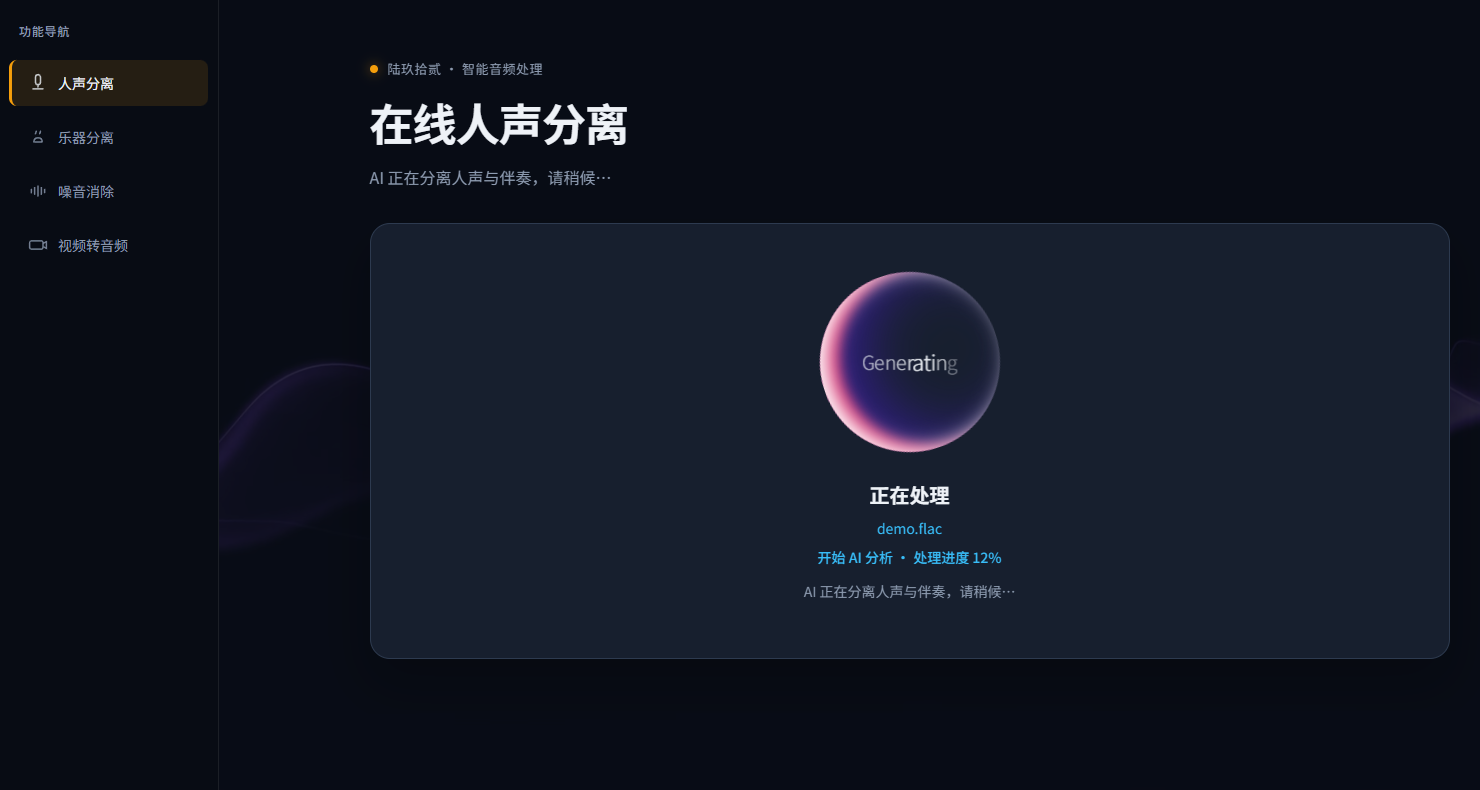
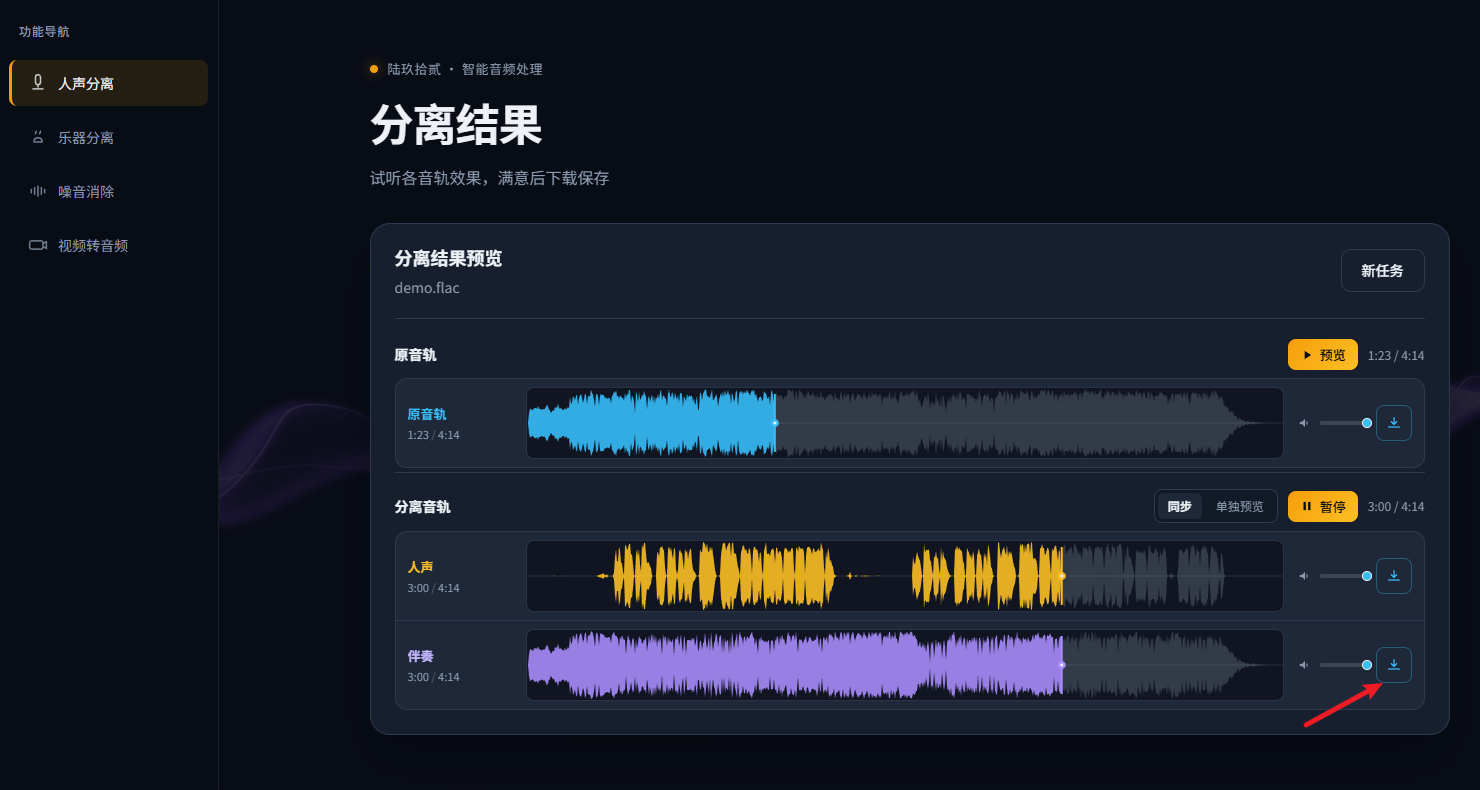
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
四、结语
怎么把音频里面的说话声和音乐分开?无论是音乐制作、影视后期,还是语音识别,音频分离技术正为内容创作与处理带来革命性变革。通过选择合适的工具,用户可根据需求灵活应对不同场景。未来,随着AI技术的进一步成熟,音频分离将变得更加智能、高效,为创意产业注入更多可能性。